在寫完前兩篇文章後我發現我竟然漏講了另外一種資料預處理的方法,所以只好在加寫一篇來講最後一個預處理方法了。
最後一個預處理的方法叫做One-Hot Encodeing,它的功能是用來不存在先後順序的資料進行轉換,就和第一個預處理map()好像負責相反的工作,但雖然他們意思相反,其實轉換的功能是差不多的。
舉個例子,當有一群人進入公司求職,他們幾個全部都來自不同的大學,分別是大學1、大學2、大學3,但這些城市又沒有先後順序之分的時候,該怎麼辦呢? 這時我們就該用One-Hot Encodeing了,它的處理方式是將原本只有城市這一個因素分化成大學1、大學2、大學3三個因素,原本的表格長這樣
import pandas as pd
people = ['A', 'B', 'C', 'D', 'E',
'F', 'G', 'H', 'I', 'J']
universities = ['大學1', '大學2', '大學3', '大學1', '大學2',
'大學3', '大學1', '大學2', '大學3', '大學1']
s = pd.DataFrame({
'people': people,
'universities': universities,
})
s
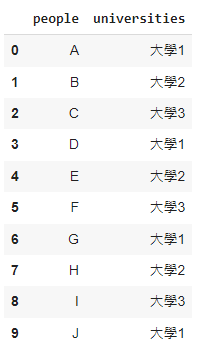
我們利用One-Hot Encodeing轉碼後
from sklearn.preprocessing import OneHotEncoder
onehot_encoder = OneHotEncoder()
onehot_encoder.fit(s[["universities"]])
city_encoded = onehot_encoder.transform(s[["universities"]]).toarray()
city_encoded

程式解釋:
第1行:導入sklearn.preprocessing中的OneHotEncoder
第2行:建立一個onehot_encoder物件,用來進行轉碼
第3行:利用fit方法將s表格中原本一欄總共有三種的叫universities的資料轉換成三欄只有一種的資料
第4行:用陣列型態儲存起來


 iThome鐵人賽
iThome鐵人賽